함수형 프로그래밍을 위한 람다 대수 입문 번역
일러두기
본 포스팅은 Raul Rojas의 A Tutorial Introduction to the Lambda Calculus을 한글로 번역한 문서입니다. 의역이 많이 포함되어 있습니다. 잘못된 번역은 댓글로 알려주시면 감사하겠습니다.
개요
이 문서는 짧고 고통없는painless 람다 대수의 입문용 문서입니다. 람다 대수라는 이 형식은 처음에는 효과적으로 계산 가능한 함수의 일부 수학적 특성을 연구하기 위해 개발되었습니다. 그러고는 함수형 프로그래밍 언어군의 강력한 이론적 기초를 제공했습니다. 람다 대수의 함수들은 이름이 없기 때문에 스스로를 외부에 나타낼 수 없습니다. 그럼에도 불구하고 람다 대수를 이용해서 어떻게 산술연산과 논리연산을 할수 있는 지를 알아볼 것입니다. 또한 어떻게 재귀 함수를 정의하는 지도 알아볼 것입니다.
1. 정의
λ(람다) 대수는 세계에서 가장 작은 유니버설 프로그래밍 언어라고 할 수 있습니다. 람다 대수는 하나의 변환규칙인 변수 대입법(베타 변환법β-conversion이라고도 한다.)과 하나의 함수 선언 문법으로 이루어져 있습니다. 람다 대수는 1930년에 Alonzo Church가 발표한 효율적인 계산을 형식화하기 위한 대수 체계입니다. 모든 계산가능한 함수가 람다 대수로 표현될 수 있다는 점에서 람다 대수는 일반적입니다. 그러므로 람다 대수는 튜링기계와 같다고 할 수 있습니다. 하지만, 람다 대수는 기호 변환규칙을 표현하는 데에만 관심이 있지, 실제로 구현하는 것에는 관심이 없습니다. 이것은 하드웨어적이라기 보다는 소프트웨어적인 접근입니다.
람다 대수의 핵심개념은 표현식expression입니다. 명사name는 목적에 따라 a,b,c같은 어떤 문자도 될 수 있는 식별자입니다. 표현식이라는 말은 단순하게 어떤 명사를 나타낼 수도 있고, 함수를 나타낼 수도 있는 말입니다. 함수에서는 그리스 문자 λ를 사용해서 함수의 인자를 표시할 수 있습니다. 함수의 "몸체"body는 인자들을 어떻게 재배열하는지를 명시한 것입니다. 항등함수(f(x)=x)를 람다 대수로 표현하면, (λx.x)와 같이 나타냅니다. “λx”는 함수의 인자가 x임을 알려줍니다. x는 함수의 몸체에 명시된 대로 변하지 않고 "x"로 반환됩니다.
함수는 다른 함수에 적용할 수 있습니다. 예시로 함수 B에 함수 A를 적용한 식은 AB로 나타냅니다. 본 문서에서 영어 대문자들은 함수를 뜻하기 위해 사용합니다. 사실 λ-대수의 모든 관심은 함수에만 있습니다. 심지어 숫자나 논리값도 함수입니다. 그 말인즉슨, 숫자나 논리값도 또다른 함수에 적용해서 또다른 기호의 문자열을 반환할 수 있다는 것입니다. λ-대수에 타입이라는 것은 없습니다. 모든 것은 함수이고 모든 함수는 서로를 서로에게 적용할 수 있습니다. 그렇기 때문에 프로그래머는 계산을 센스있게 해야하는 책임이 있습니다.
표현식expression은 다음과 같이 재귀적으로 정의됩니다.
식expression은 명확성을 위해 괄호로 묶일 수 있습니다. 하나의 식 E는 (E)로 표현할 수 있습니다. 이 언어에서 쓰는 유이한 키워드는 λ와 . 밖에 없습니다. 무수한 괄호로 인한 난잡한 표현을 피하기 위해 관습적으로 함수를 왼쪽부터 적용합니다. 말하자면, 아래의 식과 같습니다.
위의 람다 표현식λ expression의 정의에서도 보았다시피, 위의 두 문자열은 괄호로 묶여있든 풀려있든 잘 짜여진 함수입니다.
우리는 등호 “≡"를 A와 B는 동의어라는 뜻으로 A≡B 꼴로 사용합니다. 위에서 설명했듯이, λ 뒤에 따라오는 명사는 이 함수의 인자를 나타내는 식별자입니다. 마침표 뒤에 오는 표현식은 함수 정의의 "몸체"body라고 불립니다. (위의 경우에서 몸체는 마침표 뒤에 오는 x입니다.)
함수는 표현식에 적용할 수 있습니다. 아래의 예시는 함수를 표현식에 적용한 적용식application의 예시입니다.
위의 예시는 y에 함등함수를 적용한 함수 적용식function application을 나타냅니다. 괄호는 식을 명확하게 하기 위해 사용했습니다. 함수의 적용식을 푸는 것은 함수 몸체 안의 x에 인자 x의 값을 대입하는 것입니다. (이 경우에 인자 x의 값은 y입니다.) Fig.1은 어떻게 변수 y가 함수에 흡수되는지를 보여줍니다(빨간 줄). 또한, x를 대신해서 어디에 쓰이는 지도 보여줍니다(녹색 줄). 그 결과는 (화살표 기호가 의미하는) 리덕션reduction으로 얻을 수 있습니다. 최종 리덕션 결과는 y입니다.
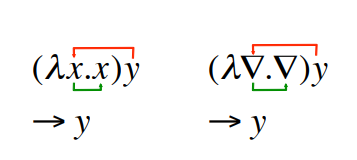
항상 Fig.1같은 그림을 가지고 있을 수는 없으므로 이제부터 모든 x에 y를 대입하겠다는 뜻으로 [y/x]를 사용하겠습니다. (λx.x)y → [y/x]x → y 인자의 명사들은 그 자체로는 아무 의미도 지니지 않습니다. 그저 자리만 차지하는 플레이스 홀더입니다. 함수가 계산될 때 인자가 어떻게 재배열되는지를 보여줄 뿐입니다. 그러므로 아래의 문자열들은 모두 같은 함수입니다.
위와 같은 종류의 순수한 알파벳 교체는 알파 리덕션α-reduction이라고 불립니다.
1.1 자유변수와 묶인 변수
우리가 처리해야 하는 표현식이 파이프라인으로 이어진 람다 표현식 그림뿐이라면, 변수의 이름을 크게 고민하지 않아도 됩니다. 하지만, 우리는 그림이 아닌 상징적인 문자를 사용하고 있고, 반복 사용에 주의해야 합니다.
람다 대수에서 모든 명사는 정의 내에서만 묶여있습니다(대부분의 프로그래밍 언어처럼). 함수 λx.x에서 x는 λx 뒤에 있는 함수 정의부에서만 존재하므로, "묶여"있다고 할 수 있습니다. λ뒤에 있지 않은 명사를 "자유변수"free variable라고 부릅니다. 아래의 표현식에서 왼쪽에서 첫번째 표현식의 몸체에 있는 x는 첫번째 λ에 묶여있습니다.
또, 왼쪽에서 두번쩨 표현식의 몸체에 있는 y는 두번째 λ에 묶여있습니다. 그리고 이때의 x는 자유변수입니다. 여기서 중요한 점은 두번째 표현식의 x는 첫번째 식의 x와는 별개로 받아드려야 한다는 것입니다. 이 규칙은 Fig.2의 함수 적용식과 리덕션에 직접 파이프라인을 그려보면 쉽게 이해할 수 있습니다.
Fig.2에서는 어떻게 상직적인 표현식을(첫번째 줄) 묶인 인자가 함수 몸체 내부의 새로운 위치로 이동하는 회로의 한 종류로 해석하는 지를 보여줍니다.
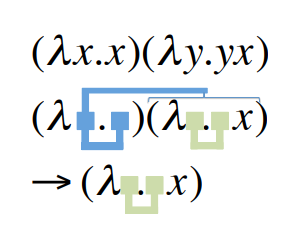
아래의 세가지 경우에서, <name>이라는 변수는 공식적으로 표현식 안의 자유변수라고 할 수 있습니다.
- <name>은 <name> 안에서 자유변수입니다.
(Example: a는 a 안에서 자유변수) - <name><name1>이면서 <name>이 <exp> 안에서 자유변수일 때, <name>은 λ<name1>.<exp> 안에서 자유변수입니다.
(Example: y는 λx.y 안에서 자유변수) - <name>이 안에서 자유변수이거나 안에서 자유변수라면, <name> 안에서 자유변수입니다.
(Example: x는 (λx.x)x 안에서 자유변수)
아래의 두가지 경우 중 하나라면, 변수 <name>은 묶인 변수입니다.
- <name>=<name1>이거나 <name>이 <exp>에 묶여있을 때, <name>은 λ<name1>.<exp>에 묶인 변수입니다.
(Example: x는 (λy.(λx.x)) 안에서 묶인 변수) - <name>이 에 묶여있거나, 에 묶여 있을 때, <name>은 에 묶인 변수입니다.
(Example: x 는 (λx.x)x 안에서 묶인 변수)
주의할 점은, 같은 표현식에서 똑같은 문자의 식별자 각각이 묶인 변수일 수도 있고, 자유 변수일 수도 있다는 것입니다.
위의 표현식에서 첫번째 y는 괄호로 묶인 왼쪽의 부분 표현식에서 자유변수입니다. 하지만, 오른쪽의 부분 표현식에서는 묶인 변수입니다. 그러므로 전체 표현식에서 y는 자유변수이면서 묶인 변수로 나타납니다. (위의 식에서 굵은 글씨는 묶인 변수들을 나타냅니다.)
1.2 대입
표준 람다 대수를 처음 공부할 때 더욱 헷갈리는 부분은 함수에 이름을 붙이지 않는다는 것입니다. 람다 대수에서는 함수를 적용할 때마다 함수의 정의를 모두 써서 계산해야 합니다. 그러나 표기를 좀 더 쉽게 하기 위해서 영어 대문자와 십진수같은 다른 문자들도 사용할 것입니다. 항등함수를 예시로 들자면 라는 문자를 항등함수 (λx.x)의 대체어로 사용할 것입니다.
항등함수에 항등함수를 적용한 적용식은 아래와 같습니다.
위의 적용식에서 첫번째 괄호로 묶인 표현식의 몸체에 있는 x는 두번째 괄호로 묶인 표현식의 몸체에 있는 x와는 독립적입니다. 위의 표현식을 아래와 같이 쓸 수 있습니다.
위의 적용식을 정리해 보겠습니다.
즉, 또다시 산출되는 항등함수를 볼 수 있습니다.

대입을 사용해서 식을 정리할 때 주의해야 할 점이 있습니다. 식을 대입하는 과정에서 자유변수를 묶인 변수와 혼동하면 안된다는 것입니다.
위의 표현식에서 괄호 안에 있는 식에서는 y가 묶인 변수입니다. 하지만 괄호 밖의 가장 오른쪽 y는 자유변수입니다. 부적절하게 변수를 대입하면, 아래와 같은 오류를 범할 수도 있습니다.
묶인 변수인 y를 t로 다시 선언함으로서 정확한 정리를 얻을 수 있습니다.
그러므로, 함수 λx.<exp>를 E에 적용하려고 한다면, <exp> 안에 있는 모든 x에 E를 대입해야 합니다. 만약 대입할때, 자유변수 E와 같은 문자를 쓰는 묶인 변수 E가 <exp>안에 존재한다면, 대입법을 사용하기 전에 다른 문자로 바꿔주어야 합니다. 예시로 하나의 표현식에 인자 x와 y가 결합된 표현식을 보겠습니다.
위의 표현식의 몸체는 아래의 식입니다.
위의 표현식을 대입법으로 정리할때, 첫번째로 나오는 x만이 y를 대입할 수 있습니다. 그러므로 대입을 진행하기 전에 묶인 변수 y를 다른 이름으로 바꾸어야 합니다.
일반적인 리덕션으로 식을 정리하려고 한다면 적용식의 가장 왼쪽의 표현식부터 정리해야 합니다. 그리고 더 리덕션할 수 없을 때까지 계속해야 합니다.
2. 산술연산
프로그래밍 언어라면 당연히 선술연산 정도는 할 수 있어야 합니다. 람다 대수에서 수는 0을 의미하는 zero부터 시작해서, 1을 의미하는 “suc(zero)” 2를 의미하는 "suc(suc(zero))"와 같이 표현합니다. 람다 대수에서 무엇인가를 표현하려면 새로운 함수로 정의해야 합니다. 숫자도 예외는 아닙니다. 즉, 람다대수에서는 숫자도 함수입니다. 숫자는 다음의 접근법을 통해 함수로 표현됩니다:
위의 함수는 두개의 인자 s와 z로 이루어져 있습니다. 위의 함수처럼 두 개 이상의 인자를 갖는 함수는 아래와 같이 축약할 수 있습니다.
위의 표현식을 적용할 때에는, s에 먼저 값을 대입한 후, z에 값을 대입합니다. 위 표현을 이용해서 자연수를 다음과 같이 나타낼 수 있습니다.
이해가 안되신다고요? 정상입니다.
왜 저렇게 나타내는 지는 앞으로 나오는 설명을 읽다보면 인정하게 됩니다.
지금은 그냥 그런갑다 합시다.λsz.s(z)는 두가지 의미로 해석할 수 있습니다.
(λsz.s)를 z에 적용한 식으로 해석할 수도 있고
sz를 인자로 받는 함수의 몸체가 s(z)라고도 해석할 수 있습니다.
본문을 읽다보니 관례적으로 (λsz.s)(z)처럼 괄호로 묶어서 표현하지 않는 이상 몸체의 일부라고 해석하나 봅니다. (정확하지는 않습니다.)
이런 방식으로 숫자를 정의하는 것의 이점은, 어떤 함수 f를 a에 연속으로 적용하려고 할 때 표현하기 편하다는 것입니다. 예시로, 함수 f를 a에 3번 적용하는 표현식은 다음과 같습니다.
이런 방식으로 숫자를 정의하는 것은 다른 언어의 “FOR i=1 to 3”과 비슷한 기능을 제공합니다. 0이라는 숫자를 인자 f와 a에 적용하면 a를 산출합니다. (0fa ≡ (λsz.z)fa → a) 이 과정을 말로 표현하자면, 인자 a에 함수 f를 0번 적용하면, 변하지 않은 a를 산출한다는 것입니다.
자연수 다음으로 알아볼 함수는 계승자successor 함수입니다. 계승자 함수는 숫자 n을 받아서 n+1을 반환하는 함수입니다.(물론 여기서 말하는 n은 람다대수 체계의 n입니다.) 이 함수는 아래와 같이 정의됩니다.
위의 정의가 이상하게 보일지는 몰라도 잘 작동합니다. 예시로 계승자 함수를 이전에 보았던 zero에 적용한 적용식은 아래와 같습니다.
위의 식에서 인자 n의 자리에 0을 대입하면 다음과 같은 리덕션 결과를 얻을 수 있습니다.
이전에 1이라고 정의했던 표현식을 얻을 수 있습니다. (묶인 변수의 문자는 크게 의미를 가지지 않는다고 했던 것을 떠올려 주시기 바랍니다.)
계승자 함수를 1에 적용하면, 2를 산출할 수 있습니다.
숫자 1 즉, (λsz.s(z))를 인자 a와 b에 적용한 유일한 이유는, 숫자의 정의 안의 변수의 문자를 a와 b로 바꾸기 위해서라는 것을 알아주시기 바랍니다.
2.1 덧셈
덧셈은, 숫자 1의 정의의 몸체안에 있는 sz를 s에 z를 적용한 적용식으로 해석함으로서 얻을 수 있습니다. 2와 3을 더하려고 한다면, 계승자 함수를 3에 2번 적용하면 되는 것입니다.
2+3을 순서대로 계산해 보겠습니다.
m 더하기 n을 계산하는 일반적인 방법은 표현식 mSn입니다.
2.2 곱셈
두 숫자 x와 y의 곱셈은 아래의 함수를 사용해서 알 수 있습니다.
3과 3의 곱은 아래와 같습니다.
위의 식을 리덕션해서 예상한 결과인 9를 얻을 수 있습니다.
이 함수가 어떻게 3과 3의 곱을 연산하는지 아해하기 위해서 아래의 다이어그램을 봐 주십시오. 첫번째 적용식 (3a)는 Fig.4의 왼쪽에서 계산됩니다. a에 3을 적용한 적용식이 a를 세번 함수의 인자에 적용하는 새로운 함수를 만든 효과를 가지는 것을 주목해 주시기 바랍니다.
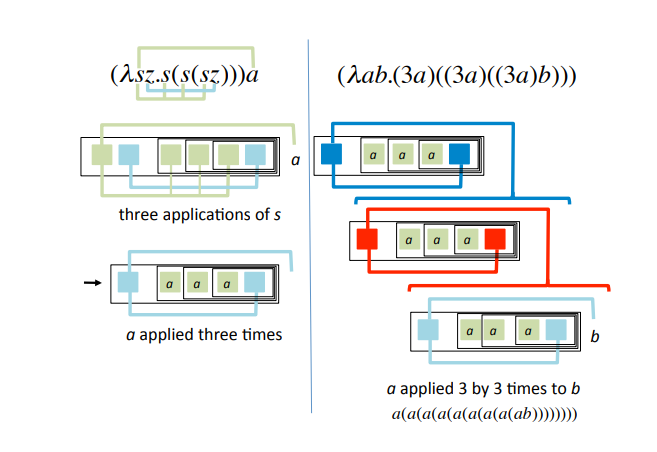
이제 함수 3을 (3a)에 적용하면, Fig.4의 오른쪽에 있는 세개의 함수 복사본을 만들어냅니다.
우리가 같은 함수 세개의 "층"을 가지고 있는것을 주목해 주시기 바랍니다. 각각의 함수는 더 낮은 함수를 함수 a를 삼중 연산한 함수에 인자로 흡수합니다. 총 9번 적용함으로써 숫자 9를 산출합니다.
3. 조건문
아래의 두 함수를 참과 거짓의 값을 가진다고 하겠습니다.
첫번째 함수는 두개의 인자를 받아서 첫번째 인자를 반환하는 함수이고, 두번째 함수는 두번째 인자를 반환하는 함수입니다.
3.1 논리 연산자
위의 T와 F를 이용해서 논리 연산자를 정의하는 것이 가능합니다.
AND 함수의 구현은 다음과 같습니다.
AND 함수의 동작 원리는 다음과 같습니다. 만약 x가 참이라면, 함수의 논리값은 y와 같습니다. 만약 x가 거짓이라면, xyF에서 두번째 인자인 F를 반환할 것이므로 y의 값에 관계없이 거짓을 산출합니다.
OR 함수의 구현은 다음과 같습니다.
OR 함수의 동작 원리는 다음과 같습니다. 만약 x가 참이라면 OR은 참입니다. 만약 x가 거짓이라면 함수의 논리값은 두번째 인자인 y의 논리값을 따릅니다.
부정 함수의 구현은 다음과 같습니다.
예시로 부정함수를 "참"에 적용해 보겠습니다.
"거짓"을 산출하는 것을 볼 수 있습니다.
위의 세가지 논리함수로 무장하면 어떤 다른 논리 함수도 구현할 수 있습니다. 또 어떠한 회로도 피드백 없이 구현할 수 있습니다. (피드백은 재귀 부분에서 다루겠습니다.)
3.2 조건 검사
한 프로그래밍 언어에서 어떤 숫자가 0이라면 참을 반환하고 아니라면 거짓을 반환하는 함수가 있다면 매우 편리합니다. 뒤에 나오는 함수 Z가 이 조건을 만족합니다.
이 함수가 어떻게 동작하는지 이해하기 위해서 아래의 식을 확인해 주시기 바랍니다.
위의 표현은 인자로 받은 a에 f를 0번 적용해서 a를 산출했다고 해석할 수 있습니다. 또 한편으로는 함수 F에 어떤 인자를 대입하던 항등함수를 산출한다는 것도 봐주시기 바랍니다.
이제 함수 Z가 올바르게 동작하는지 확인할 수 있습니다. 함수 Z에 0을 적용하면 아래와 같이 T를 산출해 냅니다. F를 에 0번 적용하면 를 반환하기 때문입니다. (0Fa = a)
Z를 0보다 큰 수 N에 적용하면 항상 F를 산출합니다. F를 표현식에 한번 이상 적용하면 항상 항등함수가 산출되기 때문입니다. (Fa = I)
그러므로 위의 식에서 N이 0보다 큰 어떤 수라면 항상 F를 산출합니다.
3.3 선행자 함수
위에서 설명한 함수들로 선행자 함수를 정의할 수 있습니다. n의 선행자를 찾으려고 할때 생각할 수 있는 일반적인 방법은, (n, n−1)쌍을 만든 다음 뒤쪽의 원소 n-1을 결과로 고르는 것입니다.
람다 대수에서 쌍 (a,b)는 다음과 같이 함수로 표현할 수 있습니다.
첫번째 항목을 추출하고 싶을때는, 이 함수를 함수 T에 적용하고 두번째 항목을 추출하고 싶을때는 함수 F에 적용할 수 있습니다.
다음으로 이어질 함수는 쌍 을 인자 로 받아서 쌍 을 생성하는 함수입니다.
라는 하위 표현식은 쌍 p의 첫번째 요소를 추출합니다. 이 요소를 이용해서 새로 만들어질 쌍의 첫번째 원소는 원본 원소의 값에서 1만큼 증가한 값이고, 두번째 원소는 단순히 원본 원소의 값이 복제된 값입니다.
숫자 n의 선행자는 함수 를 쌍 (λ.z00)에 n번 적용하고 새로운 쌍의 두번째 요소를 고르는 것으로 얻을 수 있습니다.
이 시도에서 0의 선행자는 0임에 주목해 주시기 바랍니다. 이 성질은 다른 함수들의 정의에 유용합니다.
3.4 등호와 부등호
선행자 함수를 벽돌로 삼아서 x가 y보다 크거나 같은지 시험하는 함수를 정의할 수 있습니다.
만약 y에 선행자 함수를 x번 적용한 결과가 0이라면, 가 참임을 알 수 있습니다.
만약 이고 라면, 입니다. 이 정리는 이어지는 함수 E의 정의의 기반이 됩니다. E는 두 숫자의 값이 같은 지를 알아보는 함수입니다.
비슷한 방법으로 , , 를 시험하는 함수를 정의할 수 있습니다.
4. 재귀
재귀 함수는 람다 대수에서 함수 y를 호출하고 자기 자신을 재생산하는 함수를 사용해서 정의할 수 있습니다. 아래의 함수 Y를 통해 이해도를 높일 수 있습니다.
이 함수를 함수 R에 적용하면 아래와 같습니다.
위의 식을 더 정리하면 아래와 같습니다.
위의 과정은 를 의미합니다. 그 말인즉슨, 함수 R은 재귀호출인 YR을 다시 첫번째 인자로 사용하는 함수로 계산됩니다.
한 무한반복을 예로들자면, YI는 I(YI)로 정리할 수 있습니다. 그리고 YI가 산출되고 이 과정이 무한반복됩니다. (I는 항등함수)
더 쓸만한 함수는 1부터 n까지의 자연수를 더하는 함수입니다. 이 함수를 정의하기 위해서 의 재귀적인 정의를 이용할 수 있습니다. 아래의 R의 정의를 사용해봅시다.
위의 식의 정의 중에서 은 숫자 n을 검사했을때, n이 0이라면 전체 합이 0이라는 것을 나타냅니다. n이 0이 아니라면 계승자 함수가 (r(Pn))에 n번 적용됩니다. 즉, n+r(n-1)을 반환하는 것입니다. 여기서 r은 R입니다. 즉, r은 R의 재귀호출입니다.
람다 대수에서 함수는 이름을 가지지 않습니다. 그런데 어떻게 위의 표현식의 r이 R의 재귀 호출임을 알 수 있는지 아십니까? 모릅니다. 그렇기 때문에 재귀 연산자인 Y를 사용해야 합니다. 예를들어 숫자를 0부터 3까지 더한다고 합시다. 필수적인 연산자들은 아래의 호출에 의해 실행됩니다.
3은 0이 아니기 때문에 위의 식은 아래의 식으로 정리할 수 있습니다.
그 말인즉슨, 0부터 3까지의 합은 3 더하기 0부터 (3의 선행자)(즉 2)까지의 합과 같다는 말입니다. YR의 성공적인 재귀계산이 올바른 최종결과로 인도할 것입니다.
위에서 정의한 함수에서 인자가 0이 되면 재귀가 멈춘다는 것에 주목해 주시기 바랍니다. 최종 결과는 다음과 같습니다.
최종 결과는 6입니다.
5. 독자를 위한 연습문제
- 부등호 "<"와 ">"를 두개의 인자를 받는 함수로 정의하라.
- 자연수의 쌍을 이용해서 양과 음의 정수를 정의하라.
- 정수의 덧셈과 뺄셈을 정의하라.
- 양의 정수의 나눗셈을 재귀적으로 정의하라.
- 함수 를 재귀적으로 정의하라.
- 유리수를 정수의 쌍들로 정의하라.
- 유리수의 덧셈 뺄셈 곱셈을 정의하라.
- 숫자들의 list를 나타내는 자료구조를 정의하라.
- 한 list의 첫번째 원소를 추출하는 함수를 정의하라.
- list의 원소의 갯수를 세는 함수를 재귀적으로 정의하라.
- λ대수를 이용해서 튜링머신을 묘사할 수 있겠는가?
References
[1] P.M. Kogge, The Architecture of Symbolic Computers, McGraw-Hill, New york 1991, chapter 4.
[2] G. Michaelson, An Introduction to Functional Programming through λcalculus, Addison-Wesley, Wokingham, 1988.
[3] G. Revesz, Lambda-Calculus Combinators and Functional Programming, Cambridge University Press, Cambridge, 1988, chapters 1-3.
긴 글 읽어주셔서 감사합니다. 오번역 및 기타 의견 댓글로 남겨주시면 감사하겠습니다.