SICP 연습문제 2.60 친절한 풀이
문제
앞에서는 똑같은 원소가 없는 리스트를 써서 집합을 표현한다고 하였다. 이번에는 리스트에 똑같은 원소가 나와도 된다고 치자. 그렇다면 집합 {1, 2, 3}을 리스트 (2 3 2 1 3 2 2)로 표현할 수도 있다는 말이다. 이런 표현 방식을 따르게끔 element-of-set?, adjoin-set, union-set, intersection-set 프로시저를 설계해 보자. 집합 속에 똑같은 원소가 있을 때와 없을 때, 서로 해당하는 연산들의 효율을 견주면 어떠한가? 똑같은 원소가 없는 경우보다, 이런 표현 방식에 더 잘 맞아떨어지는 문제가 있는가?
문제로 부터 얻은 것
집합의 중복을 없애지 않으면, 얼마나 게으르게 코드를 짤 수 있는지 알 수 있었습니다.
문제풀이
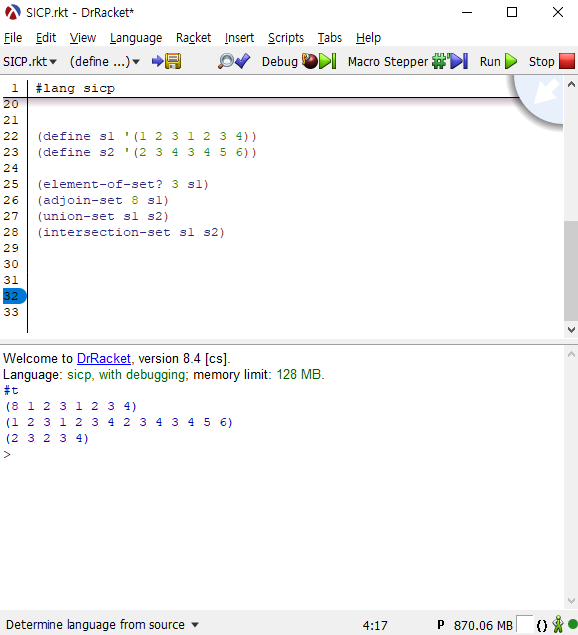
원소의 크기 순서도 고려하지 않고, 중복도 고려하지 않는다면, 짜맞추개와 고르개를 구현하는 입장에서 이보다 편할 수는 없습니다. element-of-set?과 intersection은 집합의 두 표현방법 모두에 허용되는 프로시저이므로, 기존의 프로시저를 그대로 사용하면 됩니다. 반면에 adjoint와 union은 생각나는 대로 적어서 쉽게 구현할 수 있습니다.
(define (element-of-set? x set) |
원래의 합집합과 교집합 프로시저는 시간 복잡도가 인 프로시저입니다. 하지만 새로 만든 프로시저는 시간복잡도가 과 입니다. 이는 실행 시간의 큰 차이를 불러올 것입니다. 하지만 모든 탐욕적 알고리즘이 그렇듯, 집합 연산으로 크기를 불릴 때는 쉽지만 그만큼 커진 집합으로 무엇인가 다른 연산을 하기에는 오버헤드가 커집니다. 그러므로 중복을 고려하지 않고 집합을 표현하는 방식은, 특정 원소를 찾거나 교집합 연산을 많이 하는 프로시저에서는 효율이 떨어집니다.대신 합집합과 원소 하나를 추가하는 연산이 많은 프로시저에서는 좋은 성능을 보일 수 있을 것 같습니다.
2024-03-06 수정
comolove님께서 댓글에서 지적해 주셨듯이 새로 만든 합집합과 교집합 프로시저의 시간복잡도는 과 입니다. 합집합의 경우 append 프로시저를 사용하는데, append 프로시저의 복잡도가 으로 추정됩니다. 제 서치 범위에서 공식 문서는 찾을 수 없지만, 인터넷의 여러 똑똑하신 분들께서 이라고 하시니 맞는 것 같습니다. 교집합의 경우 프로시저인
element-of-set?을 n번 사용하는 프로시저이므로, 이 맞습니다.
지적해주신 comolove님께 감사합니다.
읽어주셔서 감사합니다.