SICP 연습문제 2.70 친절한 풀이
문제
다음은 낱말 8개로 이루어진 글 집합과 그 빈도를 정리한 것인데, 1950년대에 나온 락 노래 가사를 효율적으로 인코딩하려고 설계된 것이다. (여기서 '낱말’이 되는 '글자’가 꼭 낱자가 아니어도 된다는 사실을 알아차리자.)
| 문자 | 빈도수 | 문자 | 빈도수 |
|---|---|---|---|
| A | 2 | NA | 16 |
| BOOM | 1 | SHA | 3 |
| GET | 2 | YIP | 9 |
| JOB | 2 | WAH | 1 |
generate-huffman-tree 프로시저 (연습문제 2.69)를 써서 알맞은 허프만 나무를 만든 다음에 encode 프로시저(연습문제 2.68)로 아래와 같은 글을 인코딩해 보라.
Get a job |
문제로 부터 얻은 것
허프만 트리로 인코딩하는 것이 생각보다 좋은 용량 최적화를 보인다는 것을 알았습니다.
문제풀이
a. 노래가사 인코딩
다행히도 scheme에서는 대소문자 구분을 따로 안하는 것 같습니다. 휴
우선 허프만 트리와 노래 가사를 정의하면 아래와 같습니다.
(define rock-code-tree |
앞선 문제들의 코드를 이용해서 인코딩해 보겠습니다.
(encode rock-lyrics rock-code-tree) |
인코딩한 결과는 다음과 같습니다.
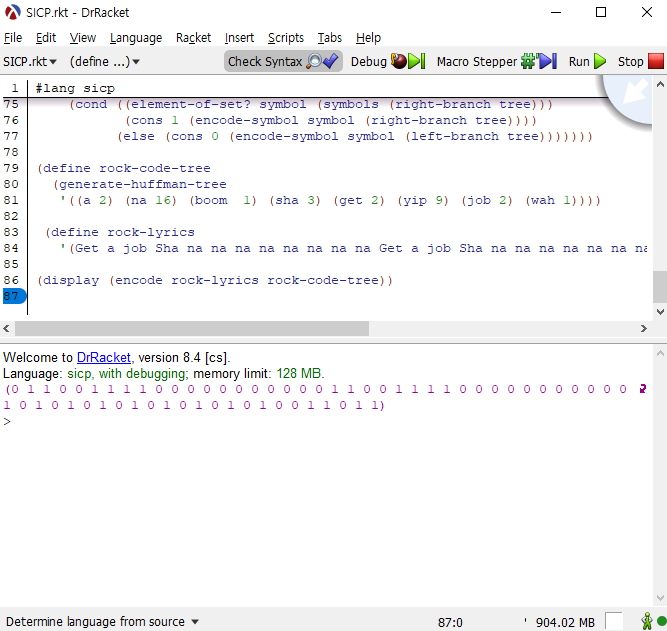
총 63개의 bit를 차지합니다.
b. 길이가 정해진 코드
8개의 단어를 길이가 정해진 코드로 인코딩하기 위해서 3bit가 필요하다는 것은 다들 아실 겁니다.
즉, 한개의 단어마다 3bit가 필요한데, 보기로 주어진 노래 가사는 총 36개의 단어로 이루어져 있으므로 가장 적은 비트수로 만들려고 해봐야 108bit나 되는 것입니다.
앞의 63bit와 비교해 보았을때 2배 가까이 차이나는 용량입니다.
읽어주셔서 감사합니다.